Group 23
- Pavan Prasad H.G. (5508053) - p.p.h.guruprasad@student.tudelft.nl
- Marnix Enting (4659147) - m.f.g.enting@student.tudelft.nl
- Marcus Malak (4451570) - m.m.h.g.malak@student.tudelft.nl
- Tishar Sinha (5277876) - T.Sinha-2@student.tudelft.nl
The link to the original paper can be found here.
Introduction
Background:
With privacy taking a center stand in all identification operations, alternative methods for driver identification have gained importance over time. Drivers’ use of turn indicators, following distance, rate of acceleration, etc. can be transformed to an embedding that is representative of their behavior and identity as it is very individualistic when compared to each driver.
We try to harness this to create a digital fingerprint of a driver based on these behaviors to assist in driver identification. But, drivers behave differently according to changing conditions and different road types, and hence a lot of training data is required to develop a highly capable system. The goal of the trained model is to detect the driver based on a short 2-second snippet of driving data.
To achieve this goal, we design a customized deep learning architecture that leverages the advantages of temporal convolution with cross-correlation, the Haar wavelet transform, triplet loss, and gradient boosted decision trees. We train this model on a dataset of driving data collected from a driving simulator designed by Nervtech, a high-end driving simulation company.
Overview of whole model:
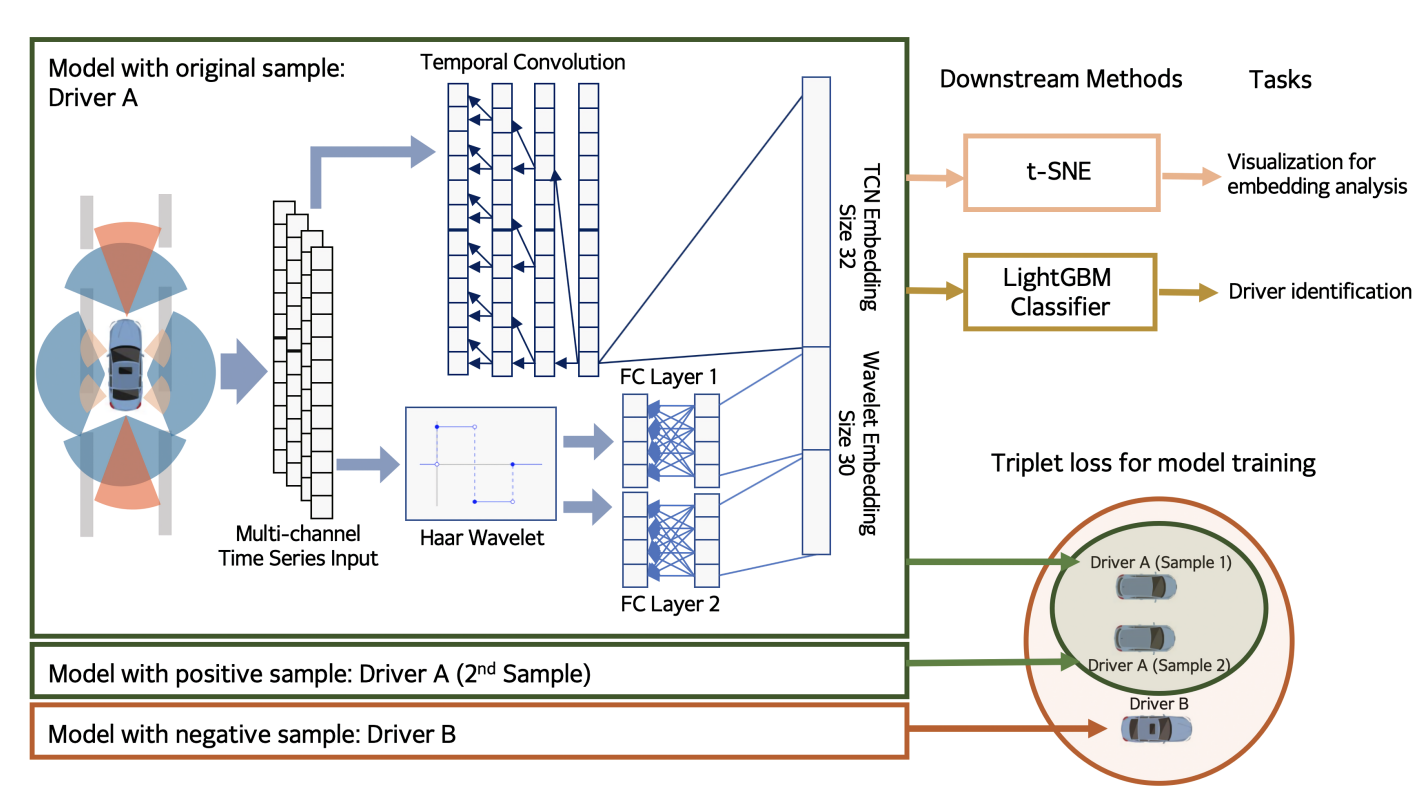
Dataset
The dataset used was collected from a driving simulator built by Nervtech that is demonstrated to reproduce an environment that invokes realistic driver reactions.
The original dataset used by the paper contained a dataset where each driver spent approximately 15 minutes on the simulator, accumulating to more than 15 hours of driving in total. However, the entire dataset was unavailable for recreation and a sample dataset containing 10 seconds of data of each driver is available. Hence, a complete recreation of the paper becomes impossible but a try of that is attempted.
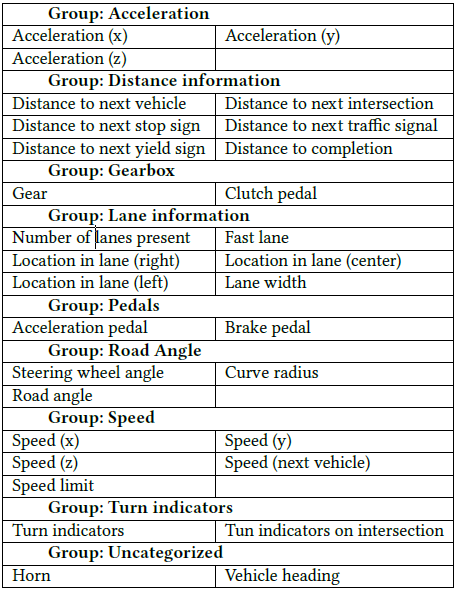
The dataset is divided into groups as shown in the below figure to assess the impact of each group on the performance of the model. Pandas data frame is used to load the model and divide it into the sub-groups. A function was created to drop the groups to perform the ablation study.
The dataset is further constructed as triplets(xr, xp and xn) as required in triplet loss. Here xr denotes an anchor point, xp denotes a positive sample of the same driver as xr, and xn a negative sample from a different driver. These triplets are used to optimize the loss using triplet loss.
Network Architecture
TCN
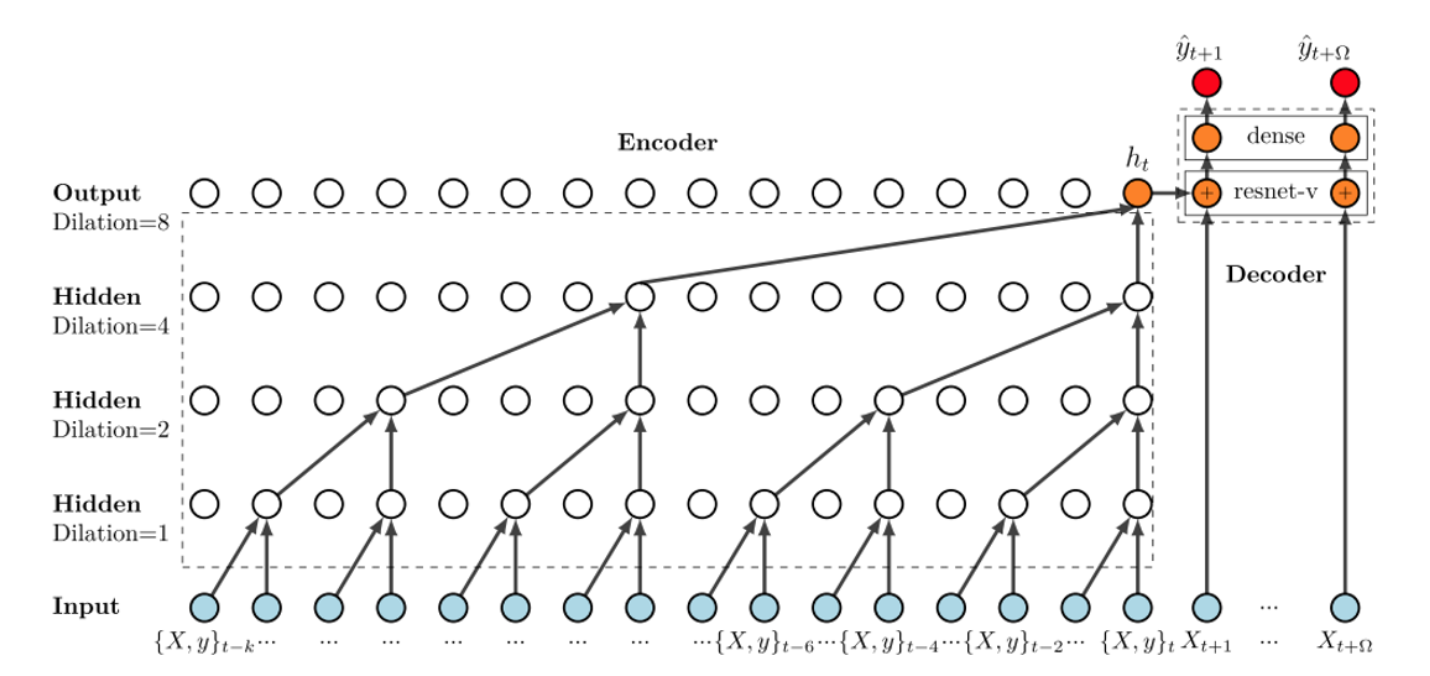
The neural network used in this paper is a Temporal Convolutional Network(TCN). This network makes use of multiple 1D fully convolutional networks stacked on top of each other. A key characteristic of the TCN is that each output at time t is only convolved with elements that are before t. In practise, this means the last element in the series can see the whole series from the beginning. The following image shows how this structure looks.
Triplet loss
The Loss function used for the TCN is triplet loss. With this loss function the reference input called the anchor is compared with a matching positive pair
and a matching negative pair
. This is done by feeding these data points through the current model and computing the distance between the anchor and its matching outputs. The loss is then defined as:
Here is the margin and
is the distance. In this model, the loss optimization objective is then to achieve
.
Haar Wavelet
The Haar wavelet transform is used as a method of indexing time series. Also known as DB1. This method is often better than discrete Fourier transform. The advantage it has over the Fourier transform is temporal resolution. It captures both frequency and location information (location in time). We use a Haar wavelet transformation to generate two vectors in the frequency domain. These vectors are cA and cD. Here cA is the approximation coefficients vector and cD is the detail coefficients vector of the discrete wavelet transform The haar wavelet returns a tuple of cA and cD. Other applications of Haar wavelet are de-noising and compression of signals and images. The output of the function is a 3-D tensor of shape (17 X 18 X 200). This is after the horizontal stacking of original data and the (cA, cD) vectors. The input of the function is the 3D dataset called train_features. The vectors from the Haar wavelet are then used as an input to a fully connected linear layer. The output then gets concatenated with the TCN output and fed to the LightGBM classifier.
LightGBM Classifier
After training the embedded model the LightGBM classifier is used to classify the 5 drivers. LightGBM is a gradient boosting framework based on decision tree algorithms that are useful for classification, ranking, etc. The main advantages of this classifier are:
- Lower memory usage
- Better accuracy
- Support parallel and GPU learning
- Faster training speed and high efficiency.
- Can handle large size of data
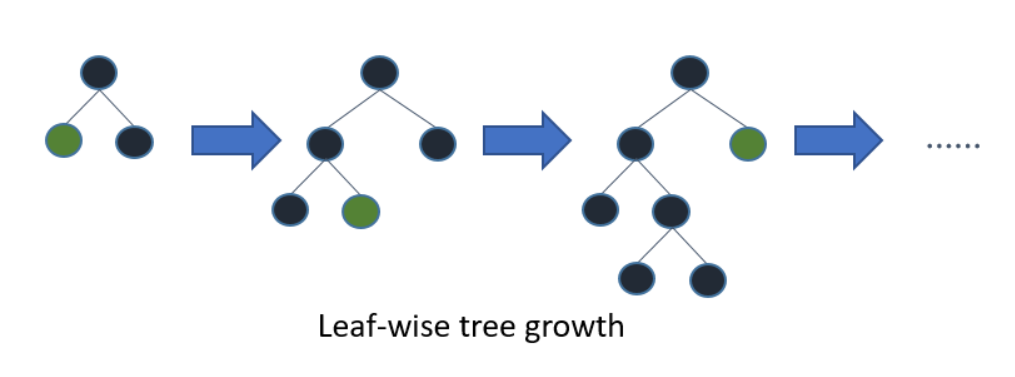
LightGBM grows tree leaf-wise while other algorithms grow level-wise. It will choose the leaf with max delta loss to grow. When growing the same leaf. This leaf-wise growth helps it to reduce the loss more than a level-wise algorithm.
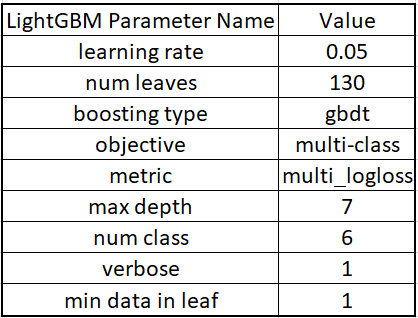
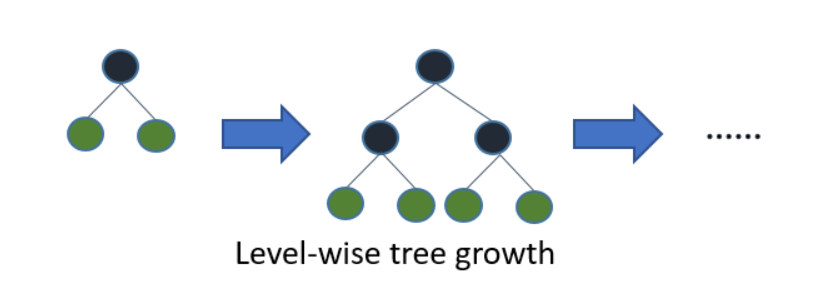 The hyperparemeter used in the classifier are:-
The hyperparemeter used in the classifier are:-
Approach taken
Model assumptions
The structure of our TCN was chosen as follows:
We have 5 TCN blocks in total. Each block contains 2 times a 1D Convolution, Chomp(remove extra padding), Relu and Dropout. These parameters were chosen to imitate the implementation of the paper. A visual representation is seen in the image below:

The input of each block has 38 channels corresponding to each input signal and the final output also has 38 channels. Each channel has two seconds of driver data which amounts to 200 data points. The ten seconds of available data were split into two-second snippets for training and testing. This was done to increase the total number of training and testing data available. The rest of the parameters used are:
- Kernel size = 16
- Padding = 2
- Stride = 1
- Dropout = 0.1
This is how the whole TCN sequence looks like:
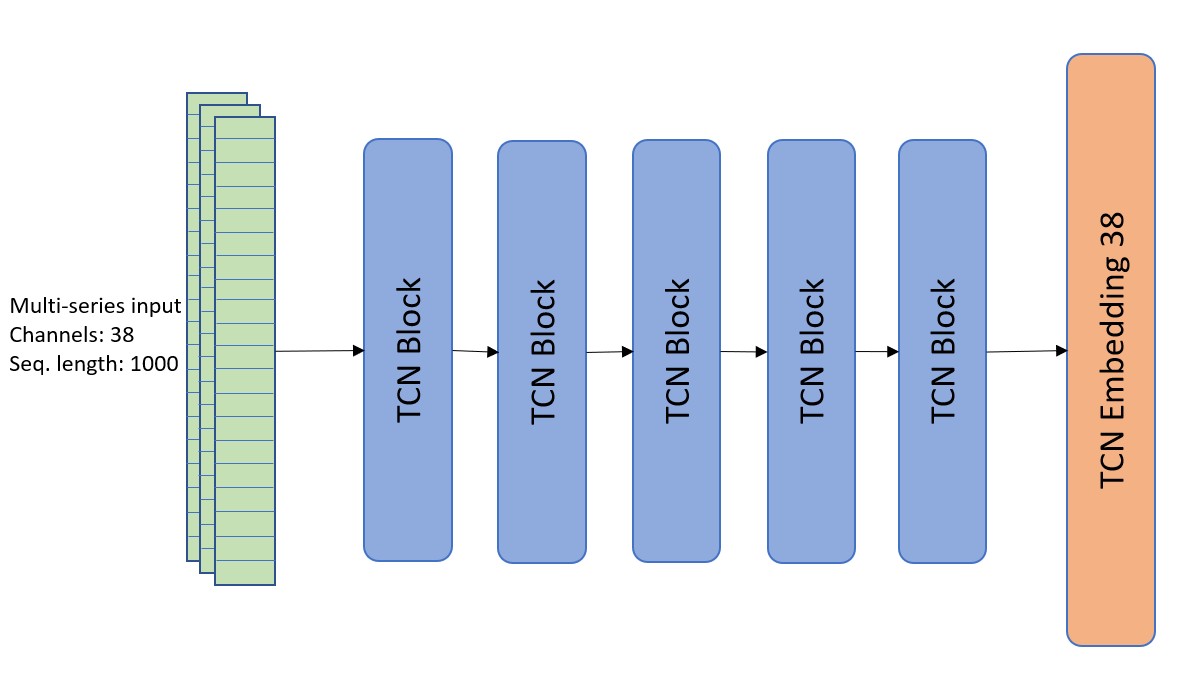
After the TCN, we use batch normalization followed by a fully connected layer to embed the output into a 1 x 38 size for the classifier.
The rest of the hyperparameters using for the model are:
Optimizer: ADAM: learning rate = 0.001
Classifier: learning rate = 0.1
Training: epochs = 100 (For reducing training time).
Results
The model was trained to optimize the triplet loss. The model was then tested with a data of 2 seconds to compute the accuracy. The overall accuracy of our model including all the feature was around 60%. However, this value was varying with different runs due to non-availability of enough data points. An ablation study was performed to calculate the pairwise accuracy by dropping certain channels mentioned in the paper.
The ablation study results are shown in the below table:

However, the results are inconsistent with runs as the test score is completely random.
The github repository can be found here: https://github.com/MarnixE/DL_reproducibility.
Discussion and Conclusion
As can be seen from the results, we were not able to fully replicate the paper. This is because, for the replication, we only had a snippet of the full dataset. To account for this, both the model and input data were altered. Namely, for the model, a simpler version was selected as it would be more prone to overfitting on this small amount of data. Likewise, the input data was split into 2 seconds instead of the ten seconds used in the paper. This resulted in less variation between the different input data. Which made the classification more trivial, as the testing data is very similar to the training data (there can only be a maximum of 8 seconds of difference between the tested datapoint and the training datapoint). However, as the model complexity is decreased and there are fewer training data, the performance of the model still decreased.
Likewise, as can be seen from the ablation study. The results vary a lot per excluded group. We believe this is caused by the hyperparameters not being optimized for the limited dataset that we use. The hyperparameters used are similar to the paper as we wanted to replicate the paper as close as possible. Also, there was not enough datapoints to train the model for the number of features available. This resulted in the somewhat random accuracy score and none of the original papers’ performance claims could be verified.
Individual Contributions
We did not keep track of individual time spent by each of the group members but we did work in pairs and the work was equally distributed between all. The person working on the specific part of the code worked on the blog for the same as well.
- Marnix worked on researching and implementing the triplet loss and data generation/extraction. He worked on the evaluation of the model post connection of all individual parameters.
- Pavan worked on data processing and the Light GBM classifier. He worked on the overall blog as well.
- Marcus worked on the research, implementation, and blog of the Temporal Convolution Networks and batch normalization.
- Tishar worked on Haar wavelets and the fully connected layers